各位早安,書接上回我們將程式碼成功加上儲存的功能,我們今天要來使它的規模更大更方便使用
首先目前我們只會建一個檔案存放資料
如果想要存取更大量資料只有一個檔案是不行的
因為記事本一旦資料太多就會變得難以閱讀
所以我今天以15頁為目標 每個檔案5頁 建3個檔案
在此之前
我們先利用之前學到的讀檔來讓終端也輸出我們抓到的內容
把原本的
print("爬完了")
改成
read = open("Pet_Get.txt", encoding="utf-8")
print(read.read())
read.close()
第一行開檔
第二行印出讀取出來的東西
第三行關檔
執行結果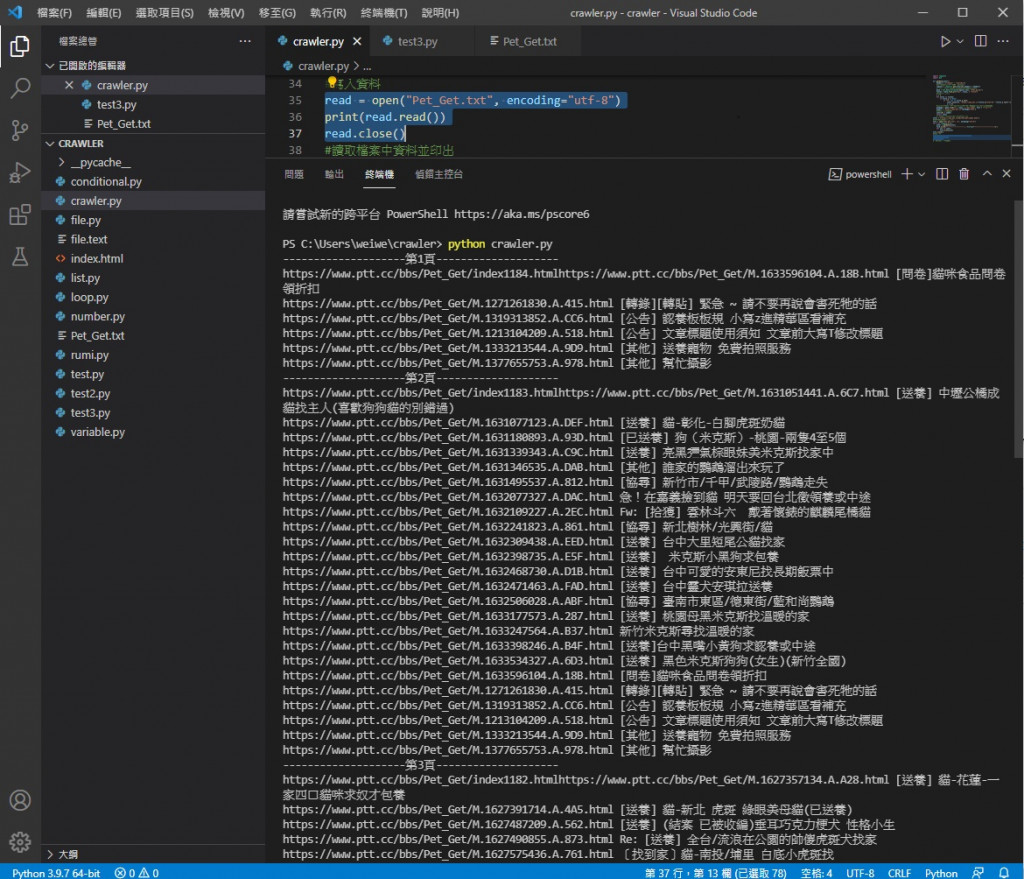
可以看到把檔案內的資料印出來了
接下來是利用多一個迴圈建立更多檔案並印出更多頁
把原本用來寫入的部分
file = open("Pet_Get.txt", "w", encoding="utf-8")
for i in range(1,4,1):
infor = getData(infor)
file.write("--------------------第"+str(i)+"頁--------------------\n")
for inf in infor:
file.write(inf)
file.close()
改成
for x in range(1,4,1):
file = open("Pet_Get"+str(x)+".txt", "w", encoding="utf-8")
for i in range(1,6,1):
infor = getData(infor)
file.write("--------------------第"+str(i)+"頁--------------------\n")
for inf in infor:
file.write(inf)
file.close()
加一層迴圈用來建立更多檔案
並把檔案名稱編號
將原本一個檔案內存三篇文章改成存五篇
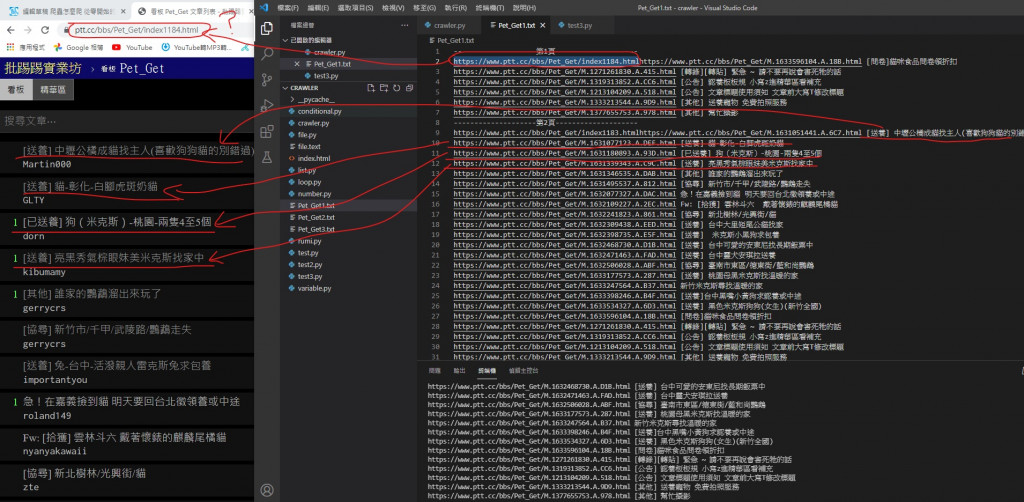
執行後可以看到他一個一個新增了3個檔案 就是這次執行的結果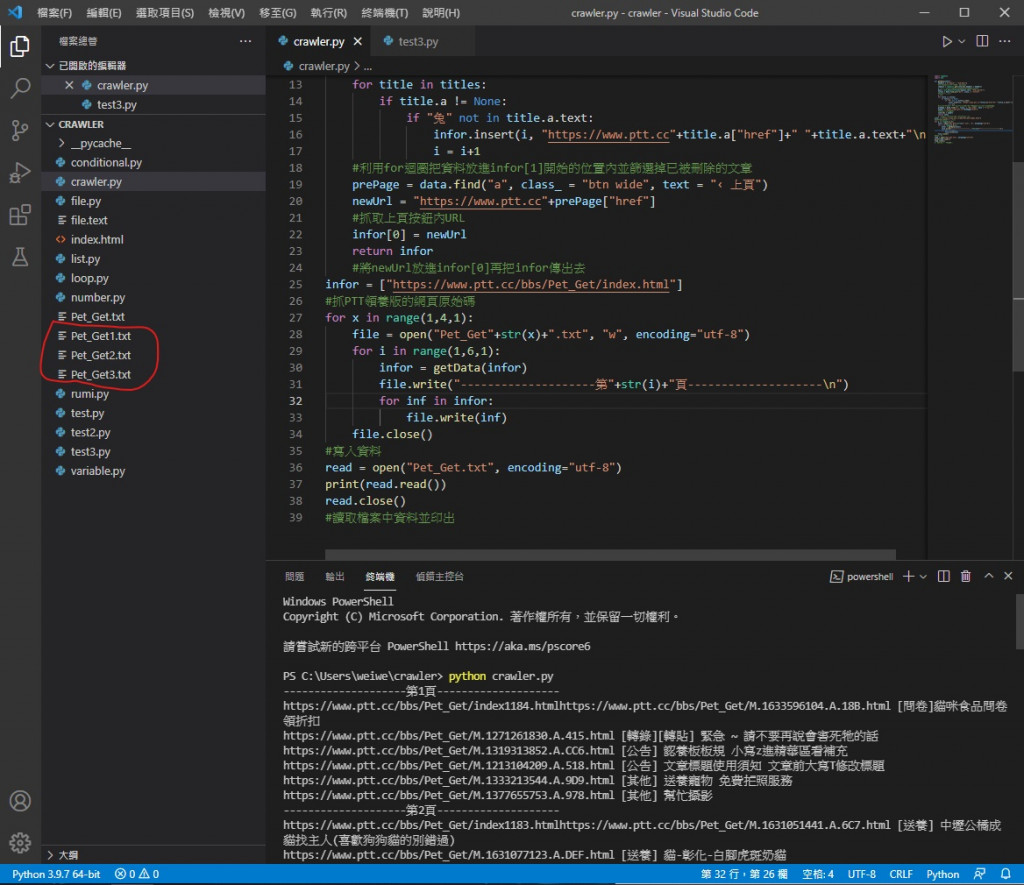
但是終端內的輸出依然沒變
因為他還是讀取之前的 Pet_Get.txt
而不是新的 Pet_Get1.txt Pet_Get2.txt Pet_Get3.txt
所以下面讀取的部分也要更新成讀這三個檔案
要加上去的迴圈邏輯跟寫入的一樣
把原本
read = open("Pet_Get.txt", encoding="utf-8")
print(read.read())
read.close()
for x in range(1,4,1):
read = open("Pet_Get"+str(x)+".txt", encoding="utf-8")
print(read.read())
read.close()
這樣就會讀取新建立的 Pet_Get1.txt Pet_Get2.txt Pet_Get3.txt 了
原本的 Pet_Get.txt 沒用了已經可以刪掉了
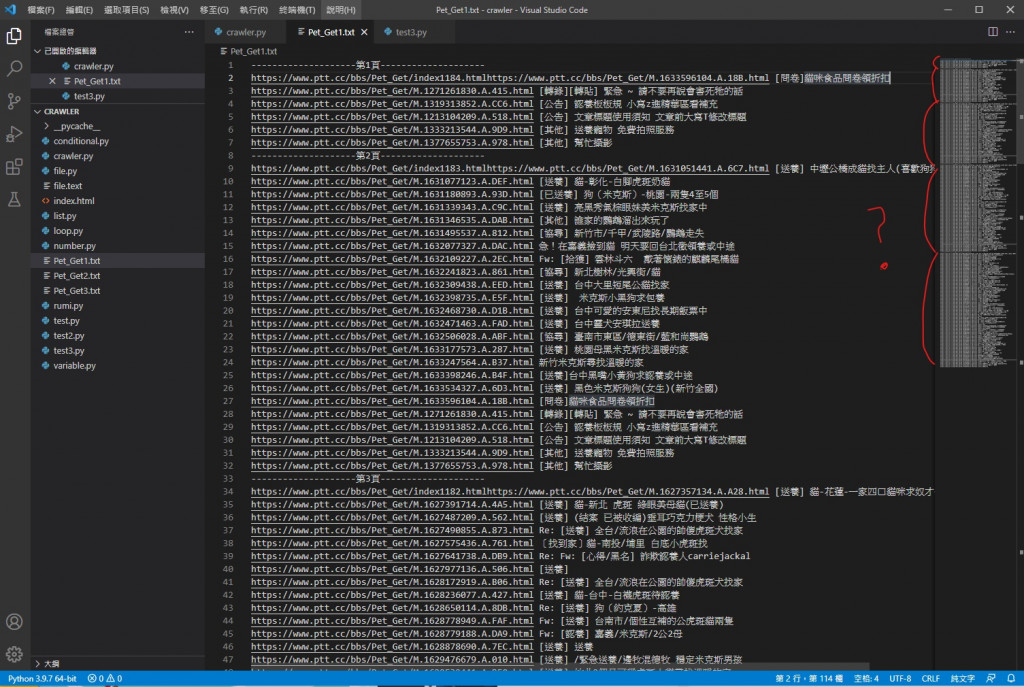
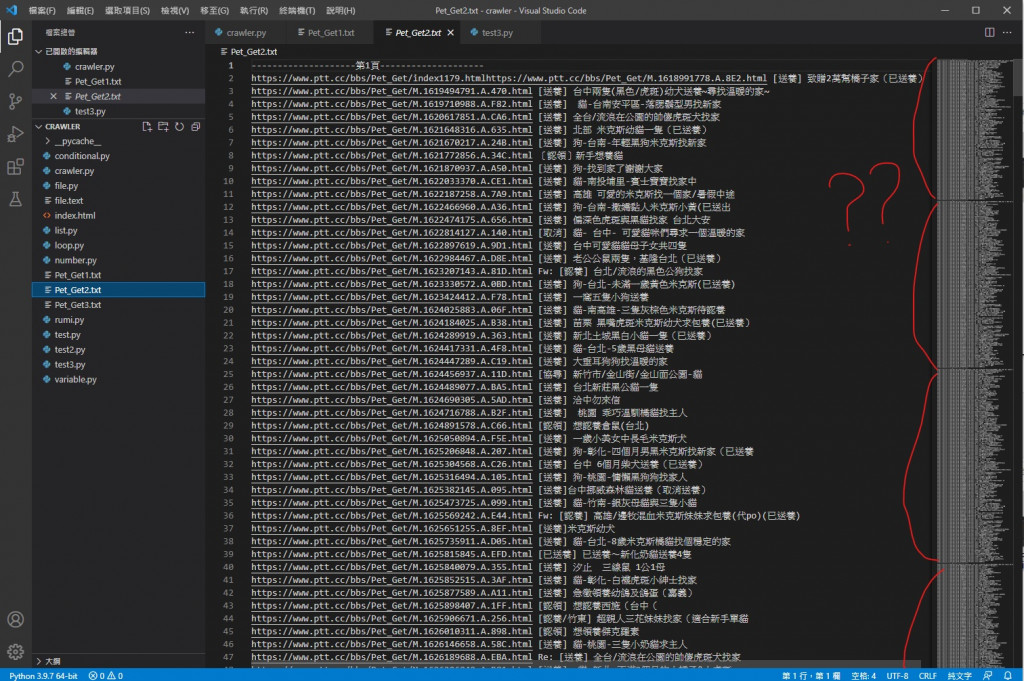
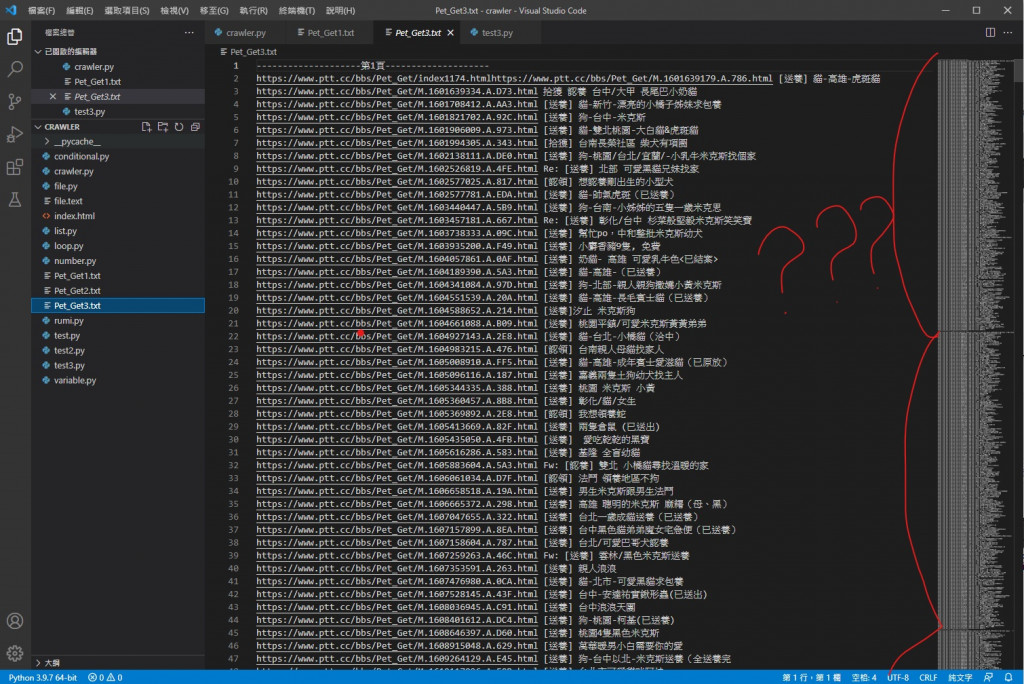
執行結果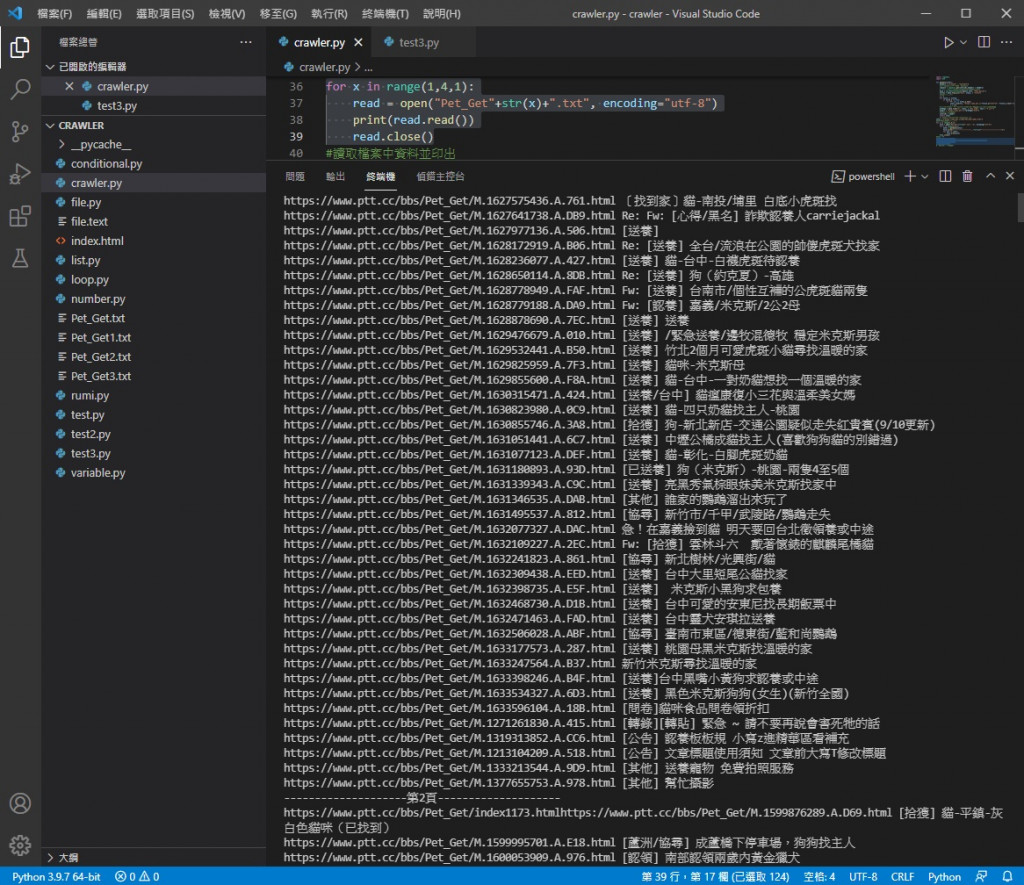
可以看到這裡印出了三個檔案量的內容 資料也都成功寫入檔案內
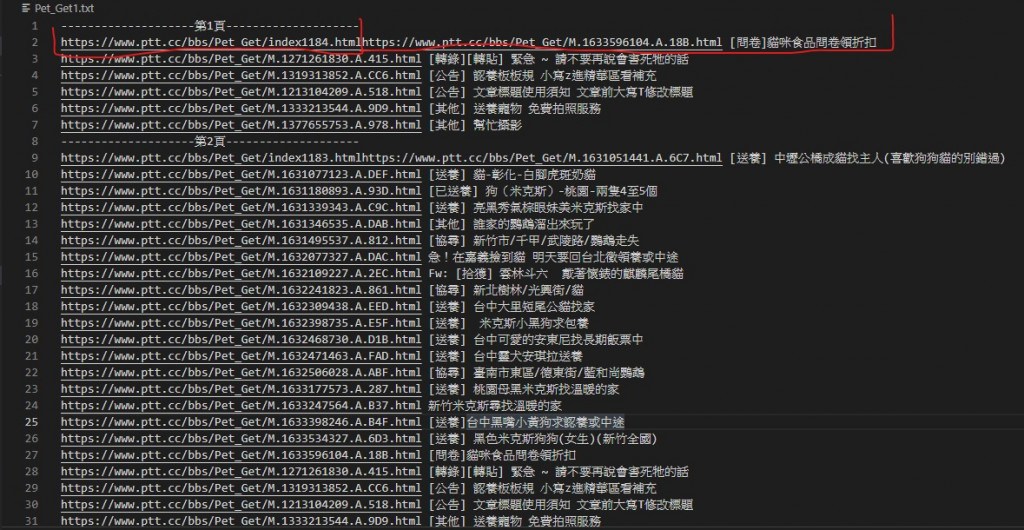
有這些問題都是我在構思程式碼時對程式設計不夠了解導致的
擴大程式的規模也讓這些原本沒發現到的問題浮現出來
有這麼多問題可不能放任它們 明天我們就要來把這些問題解決了 順便再優化一下程式
今天的程式碼
import requests
import bs4
def getData(infor):
headers = {"cookie" : "over18=1"}
#建立headers用來放要附加的cookie
request = requests.get(infor[0],headers = headers)
#將網頁資料利用requests套件GET下來並附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析網頁原始碼
i = 1
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
infor.insert(i, "https://www.ptt.cc"+title.a["href"]+" "+title.a.text+"\n")
i = i+1
#利用for迴圈把資料放進infor[1]開始的位置內並篩選掉已被刪除的文章
prePage = data.find("a", class_ = "btn wide", text = "‹ 上頁")
newUrl = "https://www.ptt.cc"+prePage["href"]
#抓取上頁按鈕內URL
infor[0] = newUrl
return infor
#將newUrl放進infor[0]再把infor傳出去
infor = ["https://www.ptt.cc/bbs/Pet_Get/index.html"]
#抓PTT領養版的網頁原始碼
for x in range(1,4,1):
file = open("Pet_Get"+str(x)+".txt", "w", encoding="utf-8")
for i in range(1,6,1):
infor = getData(infor)
file.write("--------------------第"+str(i)+"頁--------------------\n")
for inf in infor:
file.write(inf)
file.close()
#寫入資料
for x in range(1,4,1):
read = open("Pet_Get"+str(x)+".txt", encoding="utf-8")
print(read.read())
read.close()
#讀取檔案中資料並印出
歐洲古代貴族會用放射性鈾玻璃做的器皿吃飯生活導致有人生病喔
你去火鍋吃到飽是會吃爆蔬菜的草食人還是吃爆肉類的肉食人呢

